
从代码到实践:ARMv8 PMUv3性能监控的实际应用解析
 旭日财富者
旭日财富者
本文结合perf_event.c代码片段,聚焦实际开发场景,将通过以下内容展开:
1.perf工具与代码的底层关联逻辑及用法
2.常见问题(事件不支持、计数不准等)的排查案例
3.新处理器适配与定制化监控的实现方式
4.用户态性能监控工具开发要点
5.调试流程与代码关联的可视化解析(含流程图)
6.核心内容脑图梳理
一、性能工具的“幕后推手”:perf如何依赖这段代码?
perf工具的所有性能统计与采样功能,均依赖perf_event.c实现的硬件交互逻辑,核心关联场景如下:
1.perf stat:基础性能计数
以perf stat -e cpu-cycles ./app为例,代码执行流程:
•事件映射:armv8_pmuv3_map_event将上层cpu-cycles(PERF_COUNT_HW_CPU_CYCLES)映射为硬件事件ARMV8_PMUV3_PERFCTR_CPU_CYCLES。
•计数器分配:armv8pmu_get_event_idx优先为周期事件分配专属64位计数器(ARMV8_IDX_CYCLE_COUNTER)。
•计数控制:armv8pmu_enable_event配置计数器类型(armv8pmu_write_event_type)并启动计数;程序结束后,armv8pmu_read_counter读取值,经armv8pmu_unbias_long_counter修正偏置后返回给perf。
2.perf record:采样与热点分析
以perf record -e instructions -c 1000000 ./app(每百万条指令采样)为例:
•溢出配置:armv8pmu_write_counter设置计数器初始值(0x1000000 - 1000000),确保触发溢出中断。
•中断处理:计数器溢出后,armv8pmu_handle_irq读取溢出状态(pmovsclr_el0),暂停PMU避免数据skew,调用perf_event_overflow生成采样数据(含指令地址、寄存器状态)。
•数据输出:采样数据写入文件,后续可通过perf report解析热点函数。
二、实际开发中的问题排查:从现象到代码
案例1:perf提示“event not supported”(事件不支持)
现象
执行perf stat -e l1d_cache_misses ./app报错,事件无法识别。
排查流程
1.确认事件映射:检查armv8_pmuv3_perf_cache_map,L1D读未命中事件是否映射为ARMV8_PMUV3_PERFCTR_L1D_CACHE_REFILL(代码中[C(L1D)][C(OP_READ)][C(RESULT_MISS)]的配置)。
2.验证硬件支持:armv8pmu_probe_pmu通过pmceid0_el0/pmceid1_el0寄存器生成pmceid_bitmap,若ARMV8_PMUV3_PERFCTR_L1D_CACHE_REFILL对应的bit未置位,说明硬件不支持该事件。
3.处理器专属适配:若为特定处理器(如Cortex-A53),检查armv8_a53_perf_cache_map是否补充了该事件的非通用映射(部分处理器事件定义与标准不同)。
案例2:计数结果远小于预期(64位计数器异常)
现象
监控长时间运行程序,cpu-cycles计数仅为1e6(远低于CPU频率×运行时间)。
排查流程
1.64位事件判断:通过armv8pmu_event_is_64bit确认事件是否启用64位计数;若硬件不支持原生64位(armv8pmu_has_long_event返回false),需检查“链式计数器”逻辑(armv8pmu_write_hw_counter中高低32位拼接是否正确)。
2.偏置处理验证:armv8pmu_bias_long_counter需为32位计数器置位高32位(value |= GENMASK(63, 32)),若遗漏会导致高位丢失;armv8pmu_unbias_long_counter需清除高32位,确保上层读取正确。
3.中断完整性:armv8pmu_handle_irq需同时处理链式计数器的高低位溢出,若仅处理高位,会导致计数不连续。
案例3:用户态程序无法读取计数器(权限问题)
现象
自定义工具通过perf_event_open打开事件后,读取计数返回0或权限错误。
排查流程
1.用户访问开关:检查sysctl_perf_user_access(通过sysctl kernel.perf_user_access查看),需设为1以允许用户态访问(对应代码中armv8_pmu_sysctl_table的配置)。
2.寄存器配置:armv8pmu_enable_user_access需设置pmuserenr_el0寄存器(ARMV8_PMU_USERENR_ER | ARMV8_PMU_USERENR_CR),若未配置,用户态读取会触发陷阱。
3.事件标记:事件需带有PERF_EVENT_FLAG_USER_READ_CNT标记(代码中event->hw.flags设置),否则armv8pmu_user_event_idx会拒绝用户态访问。
三、新处理器适配:从代码到落地
为新ARMv8处理器(如定制化Cortex-A78)适配性能监控,需修改以下核心逻辑:
1.新增专属事件映射
若处理器有特有事件(如“LLC预取命中”),需定义专属映射表:
// 新处理器专属缓存事件映射staticconstunsigned armv8_custom_perf_cache_map[][][] = {PERF_CACHE_MAP_ALL_UNSUPPORTED,[][C(OP_PREFETCH)][C(RESULT_HIT)] = CUSTOM_PERFCTR_LLC_PREFETCH_HIT,// 特有事件};
2.实现事件映射函数
关联通用映射与专属映射:
staticintarmv8_custom_map_event(structperf_event *event){return__armv8_pmuv3_map_event(event, NULL, &armv8_custom_perf_cache_map);}
3.注册处理器初始化函数
通过宏PMUV3_INIT_SIMPLE绑定初始化逻辑:
PMUV3_INIT_SIMPLE(armv8_custom)// 生成armv8_custom_pmu_init函数staticintarmv8_custom_pmu_init(structarm_pmu *cpu_pmu){returnarmv8_pmu_init_nogroups(cpu_pmu,"armv8_custom", armv8_custom_map_event);}
4.扩展硬件探测逻辑
在__armv8pmu_probe_pmu中读取处理器特有寄存器(如pmceid2_el0),扩展pmceid_bitmap以支持新事件:
// 新增特有寄存器读取if(cpu_pmu->pmuver >= ID_AA64DFR0_EL1_PMUVer_V3P6) {u32pmceid2=read_sysreg(pmceid2_el0);bitmap_from_arr32(cpu_pmu->pmceid_bitmap +64, &pmceid2,32);// 扩展bitmap}
四、用户态监控工具开发:基于代码的能力扩展
若需开发轻量用户态工具(替代perf部分功能),可基于以下代码逻辑设计核心流程:
1.事件创建(perf_event_open)
•工具调用perf_event_open传入事件类型(如PERF_COUNT_HW_CPU_CYCLES),内核调用armv8pmu_get_event_idx分配计数器,armv8pmu_set_event_filter设置过滤条件(如仅监控用户态:config_base |= ARMV8_PMU_EXCLUDE_EL1)。
2.计数读取(read)
•工具通过read系统调用读取计数,内核最终调用armv8pmu_read_counter,经armv8pmu_unbias_long_counter修正后返回值。
3.采样处理(mmap)
•若设置采样周期(attr.sample_period),计数器溢出时,armv8pmu_handle_irq生成采样数据并写入mmap共享内存,工具可实时读取解析(如获取热点指令地址)。
五、调试流程可视化:从问题到代码的映射
针对“计数偏小”这一高频问题,结合代码逻辑的调试流程如下,每个节点均标注了需重点关注的函数与寄存器:
流程图关键说明
1.64位事件判断:armv8pmu_event_is_64bit通过事件类型(如PERF_COUNT_HW_CPU_CYCLES)和硬件能力(armv8pmu_has_long_event)决定是否启用链式计数。
2.链式计数器拼接:armv8pmu_write_hw_counter需将64位周期值拆分为高低32位,分别写入两个通用计数器(如PMCCNTR_EL0的扩展计数器)。
3.中断处理验证:armv8pmu_handle_irq需读取pmovsr(溢出状态寄存器),确认高低位计数器的溢出标志均被处理,避免漏计。
4.32位偏置修正:armv8pmu_bias_long_counter置位高32位是为了防止32位计数器溢出时,符号扩展导致的数值错误(如0xFFFFFFFE被解析为- 2而非4294967294)。
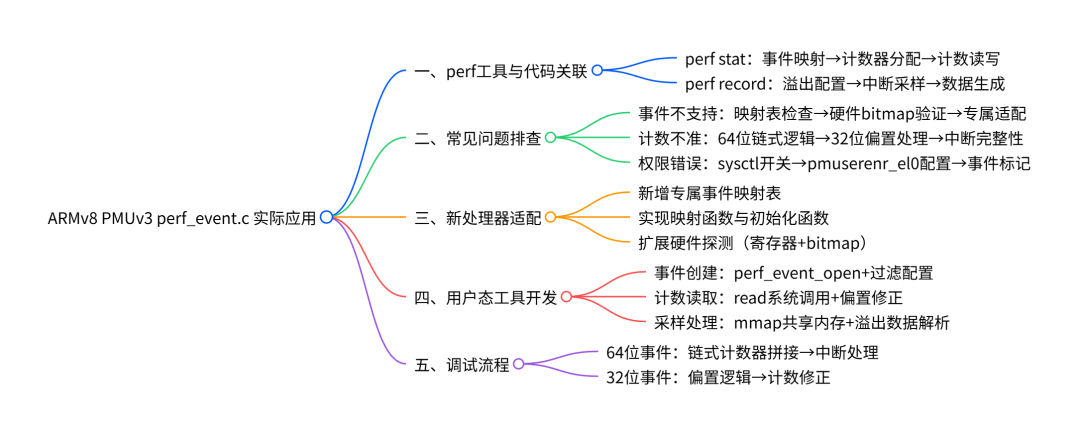
六、核心内容脑图梳理
七、总结
perf_event.c不仅是perf工具的底层支撑,更是ARMv8性能监控的“实操手册”。其核心价值在于将硬件PMU的复杂特性(如64位计数、中断溢出)封装为上层可调用的接口,而调试的关键则是打通“现象→代码→硬件”的链路——例如从“计数偏小”定位到armv8pmu_write_hw_counter的拼接逻辑,从“权限错误”关联到pmuserenr_el0寄存器配置。
掌握这些细节后,开发者不仅能高效解决perf工具的使用问题,更能基于此实现定制化监控(如新增处理器特有事件、开发轻量用户态工具),最终从“工具使用者”升级为“性能调优专家”,为ARMv8平台的系统优化提供坚实支撑。